Pearl Jam - Vitalogy
After two weeks of Christmas music, the decidedly non-holiday Vitalogy by Pearl Jam hit #1 after three weeks on the chart.
I listen to Pearl Jam relatively frequently, but not that often to Vitalogy. It has a few good songs, like Better Man and Corduroy, but overall it's nowhere near as good as Ten. Of course, that's not exactly fair because Ten is one of the best rock albums ever, and one of a few that defined grunge rock.
Overall, I'd recommend checking it out, but if you don't like it as much as Ten, that's fine.
more ...Mariah Carey - Merry Christmas
Following last week's Christmas album, this week we get the album with songs everyone hears (perhaps too much of) this time of year, Merry Christmas by Mariah Carey. Hitting #3 thirty years ago, this album has sold over 18 million copies since then. To mark the importance of 30 years, Mariah Carey released a 30th Anniversary Edition which I've linked to above.
My feelings about this album largely mirror how I feel about the Kenny G album last week. At the right time and in the right way, I'm completely fine with Christmas music. Christmas music can help to set a mood and that's great. I would never pick this nor any other Christmas music to actively listen to, but in the background, it can be just the right thing.
I have no doubt that this album will continue to get plays for decades to come. The songs on this album have a permanent place on many Christmas song playlists. Between Thanksgiving and New Years, you have my permission to play it, but not necessarily listen to it.
more ...Kenny G - Miracles: The Holiday Album
Released in late November 1994, Miracles: The Holiday Album by Kenny G hit #1 as the post-Thanksgiving holiday season set in. Other than for this album, I do not purposely listen to Kenny G. According to last.fm, I listened to a Kenny G track 12 times before I listened to this album for this blog post. I'm fairly certain that those earlier plays were part of some algorithmic mix.
Luckily for Kenny G, the album buying public does not like the same things I like and he has been very successful. This album alone has sold millions of copies. Likely because this one was so successful, Kenny G has recorded three more holiday albums since this one.
As far as this album goes, I don't really have a problem with it when it's played at the right time (after Thanksgiving and before New Years), and for the right reasons (as background music). If you were to listen to this album any other time of the year, or listen to it actively, you're crazy. It's holiday mood music, and that's fine, and that's all it will ever be. Include these songs in a holiday mix and hit shuffle/play. That's as much mental energy you should give this album (which is fine!).
Please note that I'm not a grinch! I'm getting into the holiday mood! I recently purchased a copy of Festivitas and it now decorates my dock. And it will continue to decorate my dock until no later than New Years, at which point it will be turned off.

2024 Parade of Lights
Last night we attended the Boulder Parade of Lights. A loop of streets surrounding the downtown Pearl Street Mall are closed and a wide selection of groups and members of the community participate in the parade. This year my older daughter participated as a member of the Girl Scouts and she found it very fun.
Here are a few photos from the event. As always, Mr. and Mrs. Santa Claus made a visit to finish the parade.










Method Man - Tical
Hitting #4 on debut (which is as high as it will rise), Tical by Method Man is a bit of mid-90s hip hop that I never really paid attention to. Method Man is a member of Wu-Tang Clan which has been very influential for the last 30 years. I never really paid attention to Wu-Tang clan, either.
Before listening to this album, I had eight plays of Method Man on last.fm. It's up to 17 plays now, and I think it will stay there unless he gets thrown into some auto-generated mix I listen to. I like some hip hop, but even thirty years later, Method Man doesn't do much for me.
more ...Infinite Mac
Sometime in 1994 me and my father went to a small computer show in the UC Berkeley Student Union building (which appears to now be named The MLK Jr. Building). It was probably a Macintosh oriented event, and among the various tables there was a Power Macintosh 6100 on display. The first Macintosh computers used Motorola 68000 series chips, and in 1994 Apple was making a transition to PowerPC chips. The 6100 was the first Mac to use a PowerPC chip, and seeing one in person was exciting. PowerPC chips promised a leap in performance, and I wanted one very badly. I had to wait at least a year to enter the PowerPC world when my father bought a PowerMac 8500.
Some time ago a Mac enthusiast released a website, Infinte Mac, that allows you to run old Mac operating systems in your browser. It starts with System 1.0, and has many releases all the way up to MacOS 9, the last version of the original Macintosh OS before they made the switch to the Unix-based OS that's still in use today. I suggest you try it out, it's really fun! I like playing with the various options because it reminds me of using and playing with computers from my childhood. The machines include quite a bit of pre-installed software. Many of the games I played actually work, which is impressive. It also shows how interfaces have evolved and mostly improved over the last 30-40 years.
The website uses various software emulators (including Basilisk II and SheepShaver) to simulate specific CPUs. To rephrase, what's happening is that the classic Macintosh system is running inside of a bit of software that, on the fly, translates old CPU instructions so that they run on a different CPU type. This is naturally less efficient than running instructions directly on a real CPU.
Recently I tried running a benchmark program (Macbench) in the emulator. Below is what I got on my M1 Max MacBook Pro. As you can see, the processor score is nearly five times faster than the PowerMac 6100 I wanted so long ago. Considering that my laptop has ten cores, my laptop is roughly 50 times faster than the PowerMac 6100 while running in emulated mode. It's been 30 years and of course progress progresses, but I still find it super impressive how much faster my laptop is using software emulation. Sitting here on my lap is a machine that's orders of magnitude better than what my 14 year old self wanted so badly. Huzzah!
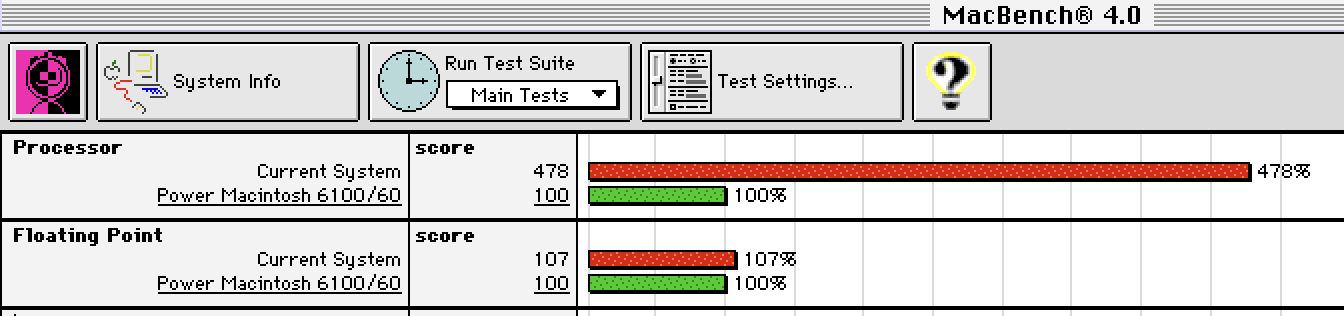
Earlier this month I bought a Mac Mini M4 to replace our six year old Mac Mini i3. As you can see, the M4 is over seven times faster than the PowerMac 6100. Being three generations newer than my laptop, it naturally gets a better score.
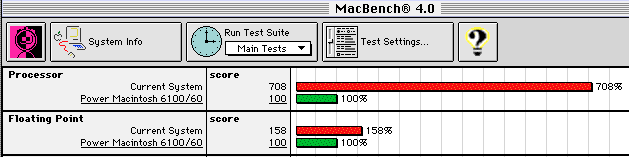
As an aside, I think that the floating point functions must be emulated in a less efficient way than the main processor functions. I don't think that the relatively low floating point scores are representative of the actual M1/M4 CPU performance.
more ...Eagles - Hell Freezes Over
For the third time in four weeks, an album debuts at #1. Hell Freezes Over by the Eagles marked their return to recording and performing together after a fourteen-year break up/hiatus. The album is in two parts. The first four songs are new material recorded in a studio. The remaining eleven songs are all live versions of older songs. This is the second Eagles album I've reviewed; I did Eagles Live almost 14 years ago.
Unlike The Dude, I do not hate the f-in Eagles, man (*). According to last.fm, I have listened to the Eagles over 1800 times. I haven't listened to Hell Freezes Over very much, around 40 times as of this writing. I think that's because there's only four new songs and the rest are live versions, and in general I prefer studio versions of songs. The new songs are pretty good, both Get Over It and Love Will Keep Us Alive charted well on the radio. The live versions are interesting, with different instrumentation and arrangements than the studio versions.
Overall my recommendation is to listen to the Eagles, and listen often. Hell Freezes Over isn't bad, and perhaps worth a listen, but their other albums are much better.
(*) I made a Big Lebowski reference in my previous Eagles review, too!
more ...Shelby American Collection

Today I visited the Shelby American Collection museum. It's in the Gunbarrel part of Boulder. I've seen signs for the museum for years but I never thought much about it until today when I decided to check it out. Honestly, I'm pretty happy I did! The museum contains a fantastic selection of cars created by and in honor of Caroll Shelby, who won the 24 Hours of Le Mans both as a driver and as a designer/constructor.
Caroll Shelby is a renown figure in American car racing history. The 2019 film Ford v Ferrari chronicles his efforts with Ford to build a car to win Le Mans and beat the Ferrari team after Enzo Ferrari played Henry Ford for a fool. Top Gear raced a Shelby GT500 against public transport and discussed some of Shelby's exploits during the film. The Grand Tour made a short film about the competition between Ford and Ferrari . There are many books about Caroll Shelby available to read.

Pretty much any car that was important in Shelby's history is in this museum. The red car above was his first Cobra race car. It's posed on the actual trailer used to take it to races, and the trailer is hitched to the actual car he used to pull the trailer and car. Info sheet for this car.
{kind=link}


The white car above with blue stripes (a hallmark of Shelby Mustangs) is worth more than $4 million because it was driven by Ken Miles to the first victory of a Shelby Mustang. This is probably the most valuable car I've seen in person, and it's just sitting in a office park in Boulder.

The collection also includes a number of Ford GT cars, including several GT40 models. The yellow one above was driven to a win at the 1967 12 Hours of Sebring by Bruce McLaren (who founded the eponymous F1 Team ) and Mario Andretti (who is the most recent American to win the F1 driver's championship, in 1978). Info sheet for this car.
{kind=link}

The cars above are two of the three GT40s that finished 1-2-3 in the 1966 24 Hours of Le Mans, the first win for a GT40 at Le Mans after two years of spectacular failures at the race. Famously, the #1 car (on the right) was leading the race towards the end, but Miles was ordered to ease up to allow the #2 GT40 to catch up so there could be a photo of the three GT40s crossing the finish line. Due to Miles being upset about this and easing up even more at the finish line, and the #2 car having traveled a slightly longer distance because it started behind the #1 car, the win was given to the #2 car. The #5 car (on the left) came in third, twelve laps behind. Here is the famous photograph of the three GT40s finishing together. This drama features prominently in Ford v Ferrari.
{kind=link}
If you're ever in the Boulder area I recommend taking the time to visit this museum. Shelby had no connection to Colorado nor Boulder, but apparently the group of enthusiasts who had the energy and opportunity to make this collection reside(d) here, and the best collection of Shelby artifacts is here. Below are the rest of the photos I took there.































































Nirvana - MTV Unplugged in New York
Recorded 31 years ago (to the day), MTV Unplugged in New York by Nirvana hit #1 on its first week on the charts. This was the first Nirvana album released after Kurt Cobain's death in April, 1994.
According to last.fm I have listened to this album over 160 times, so I know it quite well. In one sense, since I know this album so well, and have heard it for 30 years, listening to it now gives me no surprises. In another sense, this is the kind of album I truly look forward to during this project, the albums that bring me back to being a teenager. Obviously when I listen to albums from 30 years ago that are mostly new, it's more interesting, but a good fraction of the more interesting albums I don't like, and they're more work for me.
Nirvana is one of the most important bands of the last 35 years. If you haven't already heard Unplugged, I'm surprised, and you should go about fixing that right away. Listen on headphones or in a quiet room so you can pick up Cobain's mutterings between songs. Too many albums I review belong in the dustheap of history, Unplugged is the exact opposite, and will remain relevant for decades to come.
more ...Madonna - Bedtime Stories
Released the day I turned 15, Bedtime Stories by Madonna is in my opinion not one of her stronger albums. It's not a bad album per se, but compared to her other efforts, it's nothing special. Prior to listening to the full album, I think I had only heard two songs off of Bedtime Stores, Secret and Take a Bow. I'm pretty certain that it's been years since I heard either song on the radio. Looking at the most played Madonna songs played on Tidal and Spotify, the highest ranked song off this album is in the 30s, which shows that most of the public agrees with my opinion.
I actually do like Madonna, and I encourage listening to her music. This album can be ignored unless you really want to explore the full catalog of Madonna.
more ...Murder Was The Case Soundtrack
Debuting at #1, we have another movie soundtrack. I've reviewed soundtracks before and in a few ways it's different.
As far as I can tell, all of the big songs on the album (Murder Was The Case, What Would U Do?) appeared on other albums released before this album. Previous chart-topping soundtracks featured songs only available on the album.
Another difference is the album is longer than the movie for which it's named. The movie is only 18 minutes long, while the album is over an hour long.
As I looked through the track listing, I took a double take at the artist on the 6th and 11th tracks, Jewell. I had to check it wasn't Jewel. Both Wiki pages have "Not to be confused with Jewel(l) (singer)." at the top for obvious reasons.
Overall, I find this album fairly boring. Like the Above The Rim Soundtrack I previously reviewed, most of this is typical mid-90s rap. I think this album can be left to history.
more ...New Road Bike

In late 2013 I built a road bike (not pictured) from individual parts. I built it using a 2012 Fuji Altamira frame and fork, 11 speed Campagnolo Chorus, and Mavic Wheels. It was a fun project to source all the parts and put it together. I have enjoyed riding this bike in the 11 years since I built it.
The bike has not been without issues. A few years ago the rear derailleur broke. What broke is not important to mention here, except that in the end my father in law was able to weld a fix, and I remain appreciative of that. The bigger problem is that very shortly after I built up my bike, Campagnolo made a small change to their 11 speed products that broke backwards compatibility. A replacement to my 11 speed rear derailleur was basically impossible to find, hence the need to fix the derailleur with welding. Since then, I've known that if anything broke again, I'd either have to buy a whole new component group, or a whole new bike. In a sense, I've been on borrowed time.
In the intervening decade since I built the bike, there have been a few major changes to road bikes:
- Rim brakes have been replaced with disc brakes. I think that disc brakes are wonderful on mountain bikes, I have them on my MTB. For road bikes I think they are less crucial. The stopping power of rim brakes is more than enough for road bikes. However, disc brakes on road bikes is the direction the market has gone, probably for better (on balance) than worse.
- Electronic shifting replaced the cable actuated shifting with batteries, wires (or radio signals), and servos. Instead of levers, the shifters on the handlebars are simply buttons and moving the derailleurs is handled by a computer. I have been manually shifting for over 35 years without too many problems, but I am also not a luddite and the precision and speed of electronics are hard to beat.
- Internal cable routing runs cables inside as much of the bike structure as possible. There are aerodynamic advantages to this, and it also prevents dirt from accumulating on the cables. It also makes installing and servicing the cables much, much harder. Personally, I like the look of a bike with internal cabling.
- Tire clearance has inflated (ha!) dramatically. My Fuji can only handle 25C tires, while many modern road bikes can handle 32C or higher. Partially enabled by disc brakes (because rim brakes struggle to reach around large tires), larger tires allow for lower tire pressures that make riding more comfortable.
- Tubless tires remove the tubes inside tires. This is similar to tires on cars, except that bike tires typically have liquid sealant inside. On a mountain bike the advantages of tubeless are many, not least of which they eliminate the possibility of pinch flats. I have tubeless tires on my mountain bike and I think that they are well worth the hassle. On road bikes the advantages are less clear. The tire sealant only works at lower pressures, around 40 PSI. This means that a tubeless tire inflated to 90 PSI that gets a small leak will simply hiss out sealant (spraying it everywhere) until around 40 PSI, at which point the sealant can do its job. But then the tire is at 40 PSI, and you're squishing along on a really soft tire that's better than a fully flat tire, but not by much.
In summary, there have been a number of changes to road bikes in the last decade, most of which my Fuji either couldn't take advantage of, or wasn't worth doing. I decided it was time to get a new bike that had some or all of the new technologies.
After thinking about it for many (many) months, looking at lots of options (there is a spreadsheet), in early August 2024 I ordered a custom painted Orbea Orca road bike from a local shop. I have always liked Orbea bikes, and Orbea custom painted bikes cost the same as off-the-shelf models. Many other manufacturers charge extra for custom painting. The three month wait is fine if you already have a bike. I've always wanted a yellow and black bike, and that's what I got. I even have my name on the bike!

Of all the technologies mentioned above, the only one my bike doesn't have is tubeless tires. It is "tubeless capable," but I don't think I will do that. It has 12 speed Shimano Di2 electronic shifting with hydraulic disc brakes. The tires are 32C, quite a bit bigger than what I have on my Fuji.
The Shimano Di2 system is semi-wireless. Each shifter has a coin battery and communicates wirelessly with the derailleurs, and the derailleurs share a rechargeable battery that's stored in the seat tube. As shown below, the shifters can connect to my Garmin 530 and it can show what gear I'm in and the state of the batteries. Supposedly for average usage the derailleur battery lasts a few months, but having this view will be useful.


As I write this, I have only gone on one short ride to acquaint myself with the bike and adjust things. I think I will probably change the saddle and I may also change the seat post. I think the bike looks wonderful, it rides great, and I'm excited to ride it more. Of course, it's heading into winter here, and opportunities to ride will be less than in the summer. But that's okay, it will allow me to make sure it's set up the way I want in time for the spring and summer.
more ...Sheryl Crow - Tuesday Night Music Club
Hitting #8 on the charts after 33 weeks, Tuesday Night Music Club is Sheryl Crow's debut album. According to last.fm, I've listened to 12 Sheryl Crow tracks in the last 18 years, the majority off this album for this blog post. Clearly she is not one of my favorite artists. I don't think her music is bad, but I just don't choose to listen to it. I suspect the few random plays in the past were because of some algorithmic mix I was listening to.
The album does have two big hits: Strong Enough and All I Wanna Do, which I have heard before. I'm not entirely confident that I've heard any of the other songs on this album before.
Long story short, TL;DR, yadda yadda, my opinion of Sheryl Crow hasn't changed. I'll probably never listen to this album again. Finally, I'd rather go to Tuesday Night Racing than listen to this album.
more ...Smashing Pumpkins - Pisces Iscariot
I've listened to a fair amount of Smashing Pumpkins over the last 18 years, but before now I had never listened to this album. This album is actually a compilation which might be why I never checked it out until now. Perhaps another reason is that this album is not one of their most popular. This week it hit #4 but in the coming weeks it plunges down the order pretty quickly.
The only song off the album that was released as a single was a cover of Landslide originally by Fleetwood Mac. That cover did quite well and I remember hearing it on the radio 30 years ago, and I'm pretty sure I've heard it on the radio since then fairly consistently.
According to Wikipedia, this is one of the better reviewed Smashing Pumpkins albums. I think that the songs in isolation are all pretty good, but being a compilation the cohesion between songs isn't the best. I don't think I'll listen to this album all that much going forward mostly because other Pumpkins albums are better.
more ...R.E.M. - Monster
In the summer of 2001 I spent a couple months participating in a Research Experience for Undergraduates (REU) in the Physics Department at the University of Georgia (UGA). UGA is in Athens, Georgia, which is a wonderful little college town about two hours away from Atlanta. There are many things I remember about my time there. Having grown up in the Bay Area and it's notoriously cold summers, that was the first summer I spent in a genuinely hot place. I brought a bike and I spent a fair amount of time exploring the countryside around Athens — and this was before smartphones with GPS! The group of REU students I was in and a few faculty members took a trip to see a Space Shuttle launch, which was amazing.
As part of my preparation for spending a summer in Athens, I made a bunch of MiniDisc recordings (I had a Sharp MD-MS722), including the R.E.M. catalog. R.E.M. were students at UGA and got their start in Athens. I wanted to listen to their music while spending time in Athens.
Included in my MiniDisc library was Monster which shot to #1 in its first week on the charts. Monster doesn't have as many hits as Out of Time or Automatic for the People, really only the first track, What's the Frequency Kenneth got big radio airplay.
This is one of those albums that makes the 30 Years On project fun. Listening to this album brings me back to being in Athens, being in a new place, doing new things. It's a great album and I recommend it.
more ...